📅 Schedule A Meeting:
Rossmann operates over 3,000 drug stores in 7 European countries. Currently, Rossmann store managers are tasked with predicting their daily sales for up to six weeks in advance.
Store sales are influenced by many factors, including promotions, competition, school and state holidays, seasonality, and locality. With thousands of individual managers predicting sales based on their unique circumstances, the accuracy of results can be quite varied.
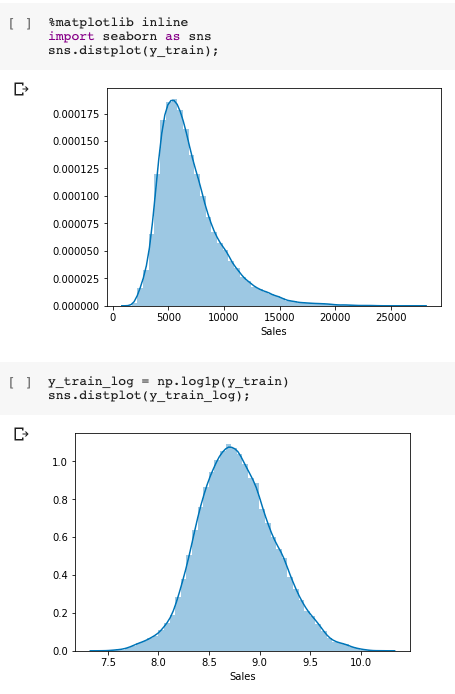
As a preprocessing step, sales (the variable I am trying to predict) is log transformed. This is done in order to make the y-variable’s distribution symmetric.
After the data is wrangled I use scikit-learn’s pipeline method combined with a random forest to fit an initial model that beats a basic mean baseline. The estimated baseline Root Mean Squared Logarithmic Error is 0.90, assuming the mean sales for every prediction.


Remember that RMSE with the log-transformed target is equivalent to RMSLE with the original target. Which columns have the greatest predictive power?
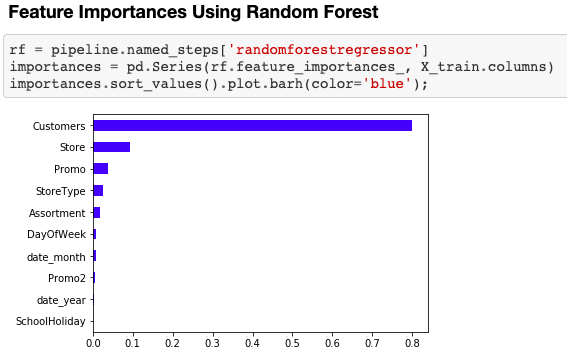
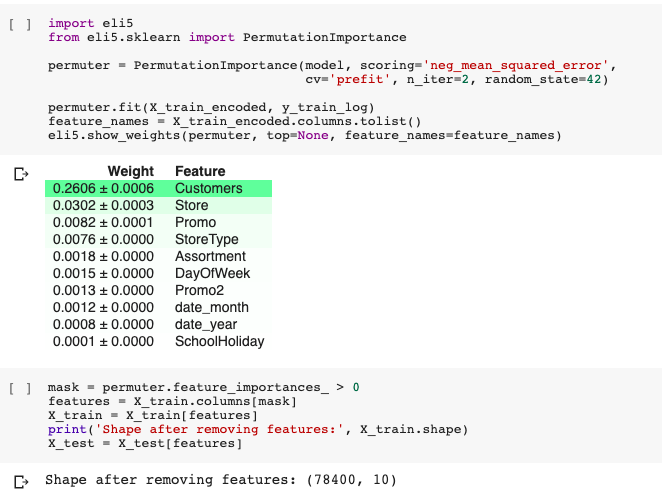
Masking in order to include only the features whose weight is greater than 0:
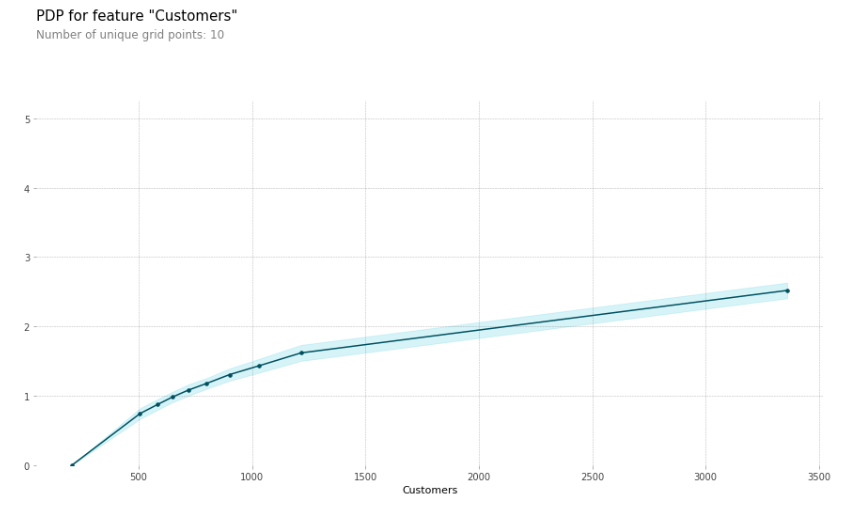
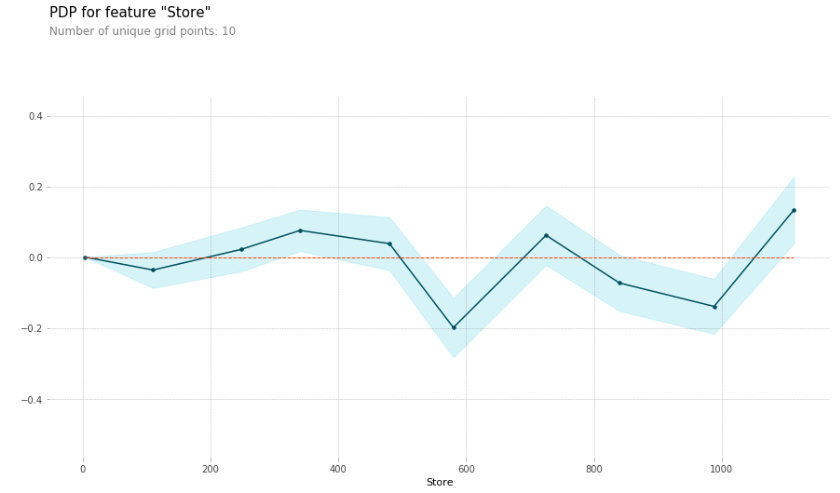
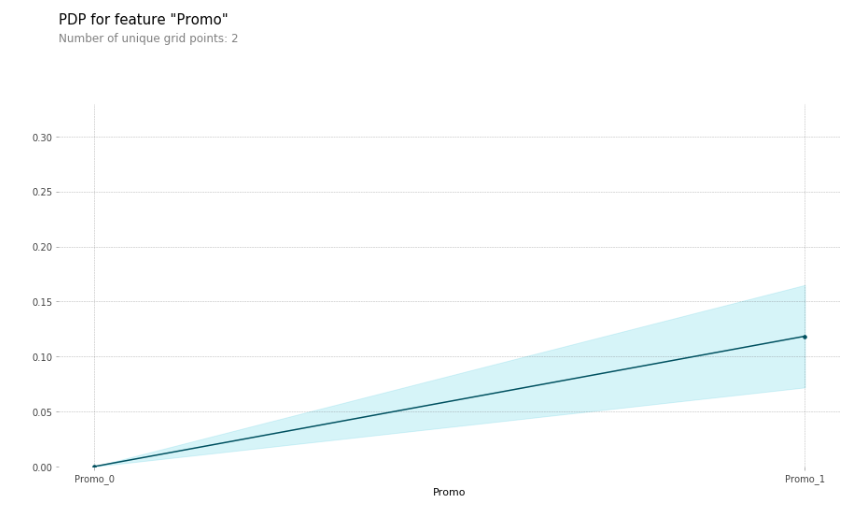
Partial Dependence Plots:
Make 💰 By Learning Programming:
- Tesla
- Liquid I.V. Hydration Multiplier 30 Stick, 16.93 Ounce
- Xeela Pre workout
- Sour Strips
- Impractical Python Projects
- Designing Data-Intensive Applications
- Python for Data Analysis
- Python for Data Science Handbook
- Hands-On Machine Learning w/Scikit-Learn & Tensorflow