📅 Schedule A Meeting:
Increasing population growth and urbanization pose serious pressure on the quantity and quality of available water. The sustainability of the present and future human life and environment depends mainly on proper water resources management.

To do this we can analyze the functional status of the available water points in Tanzania (in our case). Specifically I looked into the dataset of water pumps in Tanzania to predict the operating condition of a water point. There are three categories that classify the functional status of water pumps: functional, non functional, and non functional needs repair.
Throughout experimentation an iterative approach is utilized to progressively learn and improve upon accuracy scores. To begin my analysis I started with a naive baseline measurement the majority classifier as a fast first approach.
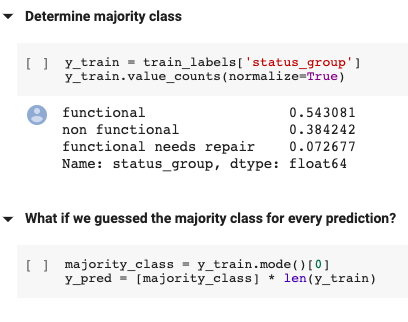

As shown above, the naive baseline model purports an accuracy score of approximately 54%. Moving forward a train/validate split is used to not only improve the performance of the model but also avoid leaks. For a detailed explanation regarding the importance of this method check out this article.
Next, the category encoders library is used to perform one-hot-encoding on categorical features of the dataset. This is a required preprocessing step in order to perform linear regression.

As we can see the model’s accuracy score increases to 65.8%.
Scikit-learn’s pipeline method is then used to manage the fit and transform operations on our split datasets. as opposed to using encoders and scalers in scikit-learn as shown above.
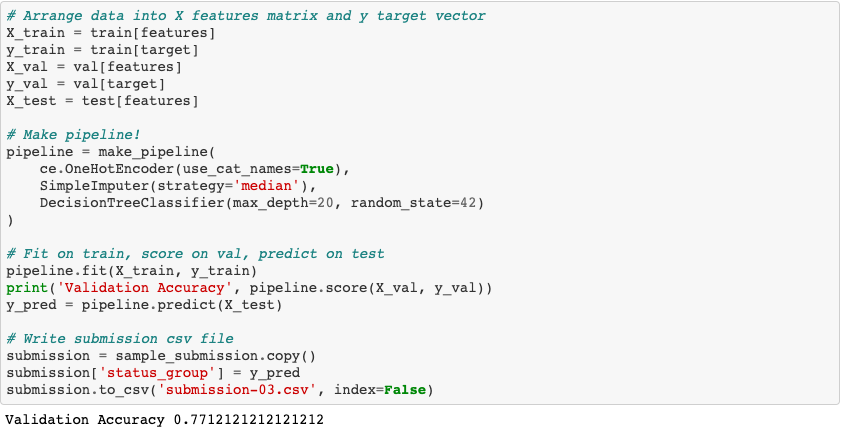
The code above depicts scikit-learn’s pipeline process showcasing yet another increase in the model’s overall accuracy score. Using the pipeline method and one-hot encoding to transform categorical variables into numeric fields yields a validation accuracy of 77.1%.
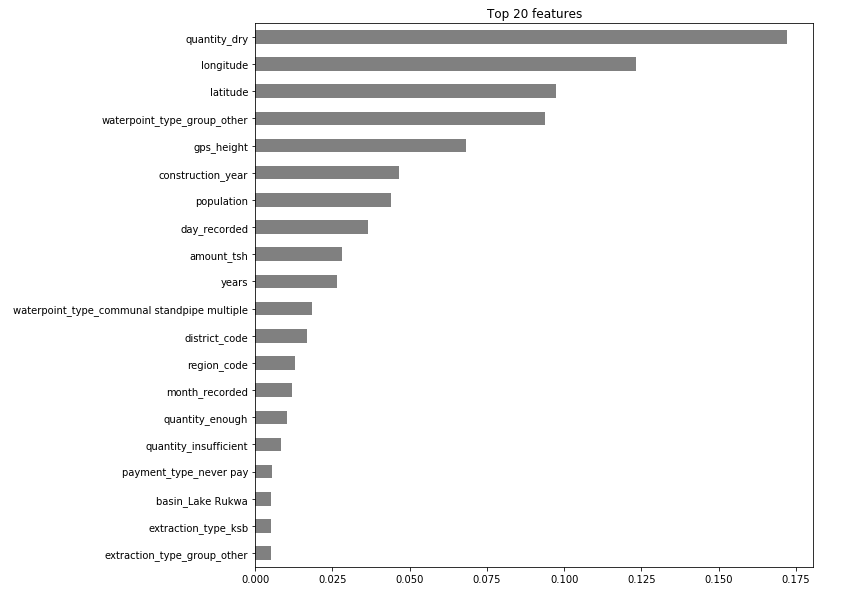
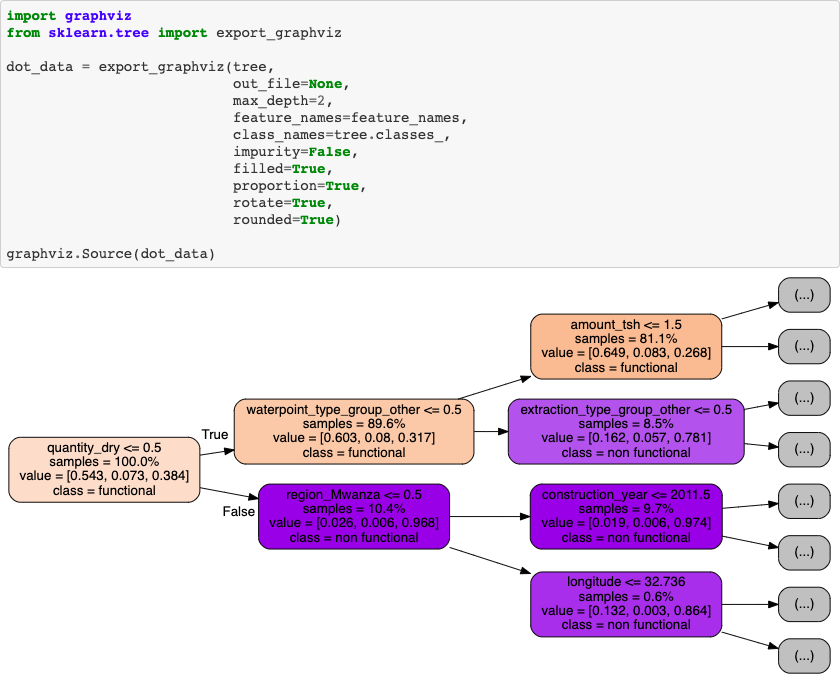
Taking a look at the model’s sorted feature importances provides deeper understanding of its predictive patterns. Another way to visualize the tree:
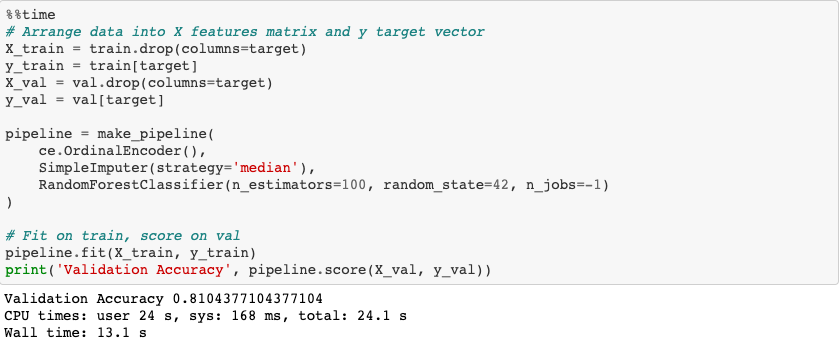
Using ordinal-encoding (as opposed to one-hot) coupled with the power of random forests yields a final overall validation accuracy score of 81%.
Make 💰 By Learning Programming:
- Tesla
- Liquid I.V. Hydration Multiplier 30 Stick, 16.93 Ounce
- Xeela Pre workout
- Sour Strips
- Impractical Python Projects
- Designing Data-Intensive Applications
- Python for Data Analysis
- Python for Data Science Handbook
- Hands-On Machine Learning w/Scikit-Learn & Tensorflow